
12月17日に、DeepSeekから小米に引き抜かれたのでは、という噂のあった羅福莉氏が、長い沈黙を破り、表舞台に姿を現しました。
彼女は、小米のAI事業の革新となる大規模言語モデルの開発責任者として、17日に開かれたパートナーミーティングにて、小米の大規模言語モデルの最新モデルである『MiMo-V2-Flash』のリリースを発表すると同時に、少し哲学的な香りのする問いから、小米のAI、そしてAIの未来について語りました。
プレゼンの全文の日本語訳版は、すでに当社noteでご紹介したのですが、このポストでは、中国語原文を掲載したいと思います。
なお、以下10段落に分けて掲載しますが、この段落分けは、読み易さを考慮して当社で行いました。
1.生物进化 VS AI逆向工程


Hello 各位开发者大家上午好,我是罗福莉。今天呢,我想带大家换一个视角。
从11亿年生物进化的长河中,重新去审视我们正在经历的这一场AI变革。如果我们回到生命进化的历程,会发现自然界在构建智能的这一座金字塔的时候,其实遵循着非常严密的一个逻辑。
在6亿年前,生命首先学会了控制身体与环境互动,紧接着进化出了多巴胺系统,通过强化学习训练进一步提升。
在两亿年前,哺乳动物的大脑首次具备了能够在行动前,先在大脑里边模拟未来的能力。
最终我们发现人类才登上智能的塔尖,掌握了语言这一抽象的符号系统。
所以我们其实能看到生物演化的规律是先具备了对物理世界的感知和生存的体验,最后才诞生了语言。
但是我们大家都能发现到现在大模型的发展路径其实是跟生物进化路径不同步的,甚至说是一种倒叙或者说是一种跳跃。
生物是先从行动进化到思考,再进化到语言,但是大模型是先学会了语言,再去补齐他的思考能力,再去最终对物理世界的一个模拟以及具身的一个感知。
2.为什么大模型它的智能的产生首先是在语言领域了?
那么,为什么大模型它的智能的产生首先是在语言领域了?
其实因为语言不仅仅是一种符号的排列组合,更是人类的思维以及对于世界的一种描述在文本领域的一个投射。
我认为这个投射它其实本质上是一种有损的压缩。
当大模型通过next token prediction这个范式在海量的文本里边进行学习,当大模型试图把Loss降到最低的时候,我们发现它不仅仅是在拟合一个统计规律,而是在去压缩人类数亿年间关于这个世界的一种认知的同构。
这种压缩的过程在我们来看就是一种智能。
所以其实大模型它是通过语言的爆发,通过去scaling计算算力scaling数据,从而去理解了人们所,人类的思维,人类关于世界的一个理解。
但其实它并不真正像人类一样具备对整个物理世界的一个感知。
所以,嗯,严谨上来说它应该是成功的去解码了人类思维在文本空间的一个投影。
但是大家都能看到其实它是一种自顶向下的一种捷径。因为它其实是学习到了一种智能的结果来去倒推智能产生的过程。
3.『MiMo-V2-Flash』研发之初主要围绕的三个关键问题。
但不管怎么说,其实语言包含了人类对世界的一个极致的压缩。
语言是智慧的结晶。
同时呢,最关键的是它高阶智能体之间高效的一个协作的工具。
因此小米也从语言出发去构建了全新一代面向agent的基座模型『MiMo-V2-Flash』。
『MiMo-V2-Flash』在研发之初其实主要围绕着三个非常关键的问题展开。
第一个,我们认为当代的智能体它必须要有一个高效的沟通语言,那么这个高效沟通语言就是代码能力和工具调用能力。
第二个就是目前智能体之间的沟通其实带宽是非常低的,那么我们如何去加速它的带宽。那么这里边就需要有一个推理效率非常高效的模型。我们需要面向推理高效率非常高效去重新设计我们的模型结构。
第三个就是其实Scaling范式已经逐步的从预训练转向了后训练。那么我们怎么去激发后训练的潜能?在后训练在强化学习上去投入到的更多的Train-time Compute。
那么这就非常需要一个稳定的后训练的范式。这三个问题是我们在构建『MiMo-V2-Flash』这一代模型去核心关注的三个问题。
4.『MiMo-V2-Flash』ーー超强的基座的潜能。
那么在这三个问题的驱动下呢,我们看到『MiMo-V2-Flash』它的一个超强的一个基座的潜能。
它虽然总参数在我看来是一个非常小的模型。我都不愿意称之它是一个非常大的模型。对。它其实总参数只有309B。激活参数只有15B。
但是它的代码能力和Agent能力在这些世界级非常公开公正的一些评估榜单上,在我来看,它已经进入了全球Top1,2。开源模型当中的全球Top1,2哈。
基本上大部分的评估的基准已经比过或者说跟「DeepSeek V3.2」、「Kimi QL Thinking」差不多。这两个模型的它的总参数量分别是『MiMo-V2-Flash』的两倍到三倍这个范围。
虽然模型小,但是我们也通过了非常多其他的优化。我后面会详细讲,达到了一种更极致的一种推理效率。
这个图呢展示了全球的大模型在全球相同水位的大模型它在价格和速度上的一个比较。
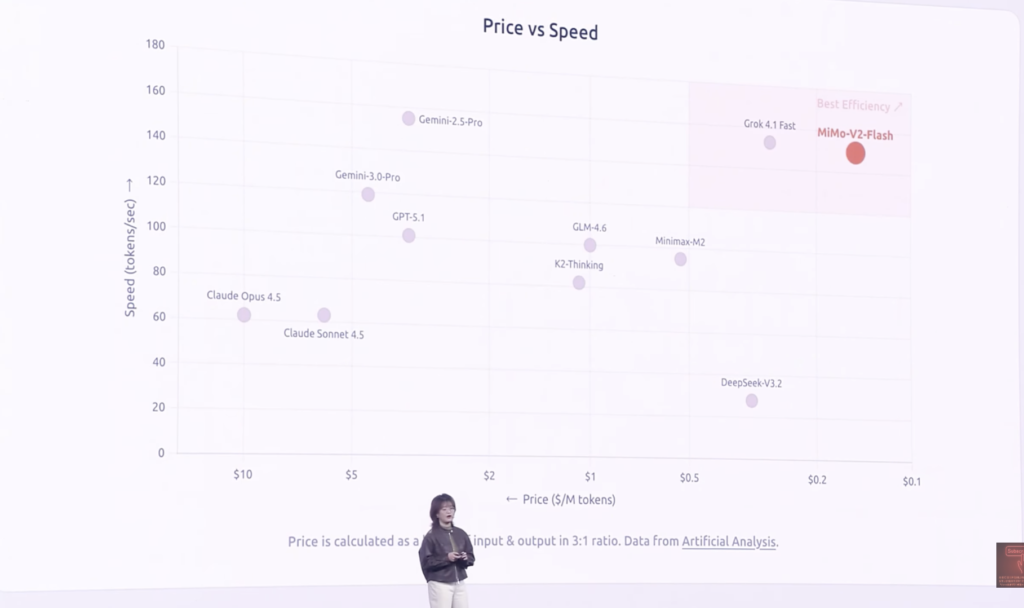
横轴呢,是它的推理价格。从大到小。纵轴呢,是它的一个推理速度。从小到大。
我们能看到MiMo它在右上表示了它具有一个低成本高速度。
举两个base line来进行对比。比如说「DeepSeek V3.2」,它的『MiMo-V2』比「DeepSeek V3.2」更便宜一点。但是呢它的推理速度是「V3.2」的大概3倍左右。
然后我们再举一个性能综合能力。跟『MiMo-V2-Flash』差不多的「Gemini 2.5 Pro」。它的整个的推理速度是跟『MiMo-V2-Flash』相当的。但是它的推理成本比『MiMo-V2-Flash』整整贵了大概20倍。对。
那么,我们是怎么做到这一切的呢?
5.『MiMo-V2-Flash』ーー两个创新(Hybrid Attension结构和MTP)
其实这里边核心的一个关键就是我们要围绕着极致的推理效率去重新设计我们的模型结构。我们的模型结构主要是依靠两个创新。
第一个是Hybrid Attension的结构。我们是Hybrid的Sliding window attension和full attension。它们的比例大概是5:1。
此外呢,我们为什么Sliding window attension,因为它看起来非常简单。它只关注领域的128个Token。
但是呢,我们发现经过大量的实验验证。我们发现一些看似很复杂的Linear Attension的结构。其实它在一些综合的性能上,比如说兼顾长短文的推理,兼顾长短文的知识检索上,其实并不如很简单的self attension。
并且Sliding window attension呢,它有一个非常好的特性。就是它的KV Cache是固定的。所以它能非常好的适配当代的非常多的infra的推理框架。
此外我们也提,我们也更好的去挖掘了下MTP的潜力。
MTP它其实很难,它其实一开始是被提出来用于做推理加速的。后面DeepSeek将它用于去提升基座模型的能力。我们也在训练的时候去加了一层MTP层提升基座模型。
进一步提升基座模型的潜能,并且呢,我们在微调的时候加入了更多层的MTP,用了很少量的算力就提升了MTP的层的接受率。
这样一种最终我们推理的时候呢,是使用了三层的MTP。这种加速并行的去进行TOKEN验证的方式呢,在我们实际的推理加速的场景里边能够做到2到2.6倍的一个实际的推理加速的一个提升。
6.『MiMo-V2-Flash』ーー反复尝试和意外的发现。
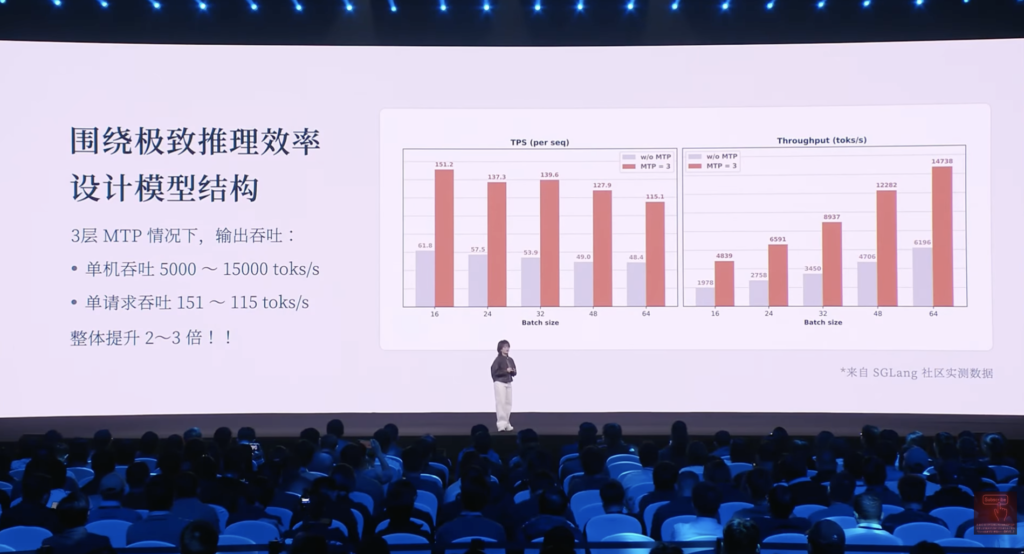
我们来看一下社区关于三层MTP的情况下它的模型输出的一个吞吐情况。模型的输出的吞吐跟成本高度密切相关的。
然后在单机吞吐我们能做到5,000到10,000TOKEN每秒的基础上,我们发现单请求吞吐也能做到105到115TOKEN每秒。
使用MTP和不使用MTP整体速度能够提升2到3倍。
就像我刚刚讲的一样,我们除了关注预训练的结构是非常高效的。那么我们怎么去充分利用这个高效的结构去扩展我们强化学习训练的computer。
这里边一个关键的是强化学习训练很多时候是非常不稳定的。
我们怎么去,因此呢,我们就提出了一个multi teacher的一个on policy的distillation的范式。
它的核心呢是在于说,它是非常on policy,它是依赖于一个dense level的,TOKEN level的一个reward来进行监督学习。通常我们post train的范式是会通过。SFT和RL拿到各个领域专家的模型。
MOPD的话会将这些专家模型会先让一个student模型去rollout基于自身的概率分布去rollout一些序列出来。然后再用专家模型对这些序列进行一个概率分布的打分。
然后提供一个非常稠密的TOKEN level的一个监督信号。我们发现这样的一个学习效率非常之高,我们能通过简短的几十步就能去将各个领域专家的一个模型的能力。快速蒸馏到这个student模型上。
此外,我们还发现一个很意外的事情,就是说当这个student很快超越这个teacher的时候,我们能不能把这个teacher替换成这个student。继续自我迭代提升。就是一个in progress的工作。
⌘
我们发现其实『MiMo-V2-Flash』在具备,它已经初步的具备在语言空间去模拟世界一个能力。
它只是通过语言去模拟它也不是真的感知到了这个世界。
就比如说,我们可以通过html让它去写一个操作系统。我们可以看到这个操作系统的很多功能其实都是可,可可,可实现的。
此外,我们也可以让它去写一个html去模拟整个太阳系,然后你甚至可以用,它来做一些小的demo。画一棵圣诞树。并且跟它产生交互。
『MiMo-V2-Flash』在昨天已经发布了。并且我们开源了我们所有的模型权重。技术报告的细节。同步了,我们也提供了一个API。然后供所有的开发者能够实时的去接入到一些web coding的IDE里边去。然后呢,同时呢,我们的体验web也上线了。大家也可以扫描进去。也跟他对话试一试。
7.下一代的智能体必须具备的潜能是?
虽然现在的大模型呢,它能聊天,能写代码,但是呢我相信大家还是很不放心把你的身边很复杂任务交给它。
因为其实我认为真正的下一代智能体的系统,它不是一个语言模拟器。它是需要跟我们的世界共存的一个智能体。
所以其实下一代的智能体,它必须具备两个潜能:第一个是它要从回答问题变成完成任务。这里边其实大家可能会在很多场合去看到说ok。它要有记忆能力推理能力自主决策规划等等,ok。但其实这些在我来看,它背后的研究的深度都很深。就是每个方向它都是有非常深的研究深度。
然后,此外的话我们相信这些能力的基础,它必须要产生交互的前提是它要有一个omni的一个感知能力。
也就是说我们做一个统一的动态系统是非常必要的。它也是为我们去理解整个世界一个很很关键的基础。
在这些基础上,当我们有了这样的一个模型的基础上时候,那么我们可以很无缝的嵌入到像眼镜这样的一些智能终端。更无缝的去融入到我们的生活流。
8.AI进化的下一个起点,本质的跨越。
回到我们一开始的讨论的话题。就是大模型其实它本质上是用了算力的暴力美学直接去攻克了最顶层的语言。第二层的强化学习。
但是呢,它跳过了中间的非常多的步骤。比如说第三层关于对世界的一个感知,对世界的模拟。以及对于第一层它必须要有个实体跟这个环境产生交互。
这也是为什么现在大家认为大模型其实它已经做到了数学奥林匹克竞赛的水平。它可能有时候也能去模仿莎士比亚的风格去写作。但是你发现它其实本质上并不太懂。重力这样的一些物理法则的含义。并且它有时候经常会产生一些具身的幻觉。也就是说其实我们现在大模型。
它其实只有一个完美的语言的外壳。它没有一个锚定现实世界的一个物理模型。
所以我认为其实AI进化的下一个起点是一定要有一个可以跟这个真实环境产生交互的一个物理模型。
我们本质上要打造的并不是一个程序,其实是一个具备在物理上一致性,时空连贯性的一个虚拟的宇宙。
这其实本质上是代表着AI的能力有一个本质的跨越。他不仅仅满足于说他要去看懂画面,而是说要理解背后的物理规律,也不仅仅局限于说ok,他要去处理文本,而是说他要去推演后边整个世界的一个运作逻辑。
我相信真正的智能绝对不是纯粹是在文本里边读出来的。而是说它在交互里边活出来。
9.MiMo,你是怎么解读关于物理世界导向?
其实我刚刚说这句话呢,它是一个非共识。
就很多人还是比较坚信,包括伊利亚他其实都比较坚信说ok。在语言空间是能够实现所谓的AGI的。
所以我也带着这样的一个,我相当于下了一个命题,我去问了一下『MiMo-V2-Flash』。
我说你是怎么解读关于物理世界导向,也就是说我们要去强调多模态和真实世界的交互是通往AGI的关键,你怎么去解读这个事?

它给我的回复是,它认为这是一个非常核心和深刻的观点。
它认为智能是要根植于存在的,而并非符号。因为符号体系里边它只能建模模式匹配,建模概率预测。它并不具备一个,而它,而MiMo认为它必须具备一个具身的嵌入式的环境。通过于这个真实的物理世界产生持续的交互,从而持续涌现更强的能力。
我觉得这其实本质上就是人类这样的一个高阶智能体它所演变的一个逻辑。
这不是我们训练进去的啊。它自,它,它自己涌现出来的能力。然后我只是突然问到一下我觉得有点让我意外。有点让我意外。
10.开源的价值,小米与全球AI的未来。
其实呢,我本质上我们认为技术上是可以追赶的算力和数据呢也并非最终的护城河。
有点奇怪吧。其实确实数据也不是。
然后真正的护城河呢,其实我认为是科学的研究和方法。是将未知的问题转化成模型的优势,最终去结合可用产品的一个能力。
小米的大模型的core团队,其实就是在这样的长期愿景中诞生的。我们构建了一个研究,产品,工程,深度耦合的一个年轻化的团队。它非常具备创业精神。
我们团队人每个人都极度好奇,追求真理,乘着自由的风,满怀着对这个世界极致的关怀,在一起去探索智能的边界
⌘
在这个演讲的结尾,我想跟大家回顾一下。
在2020年我刚去进入大模型这个领域的时候,一开始也是去做开源模型。那会的开源模型距离世界顶尖的闭源模型的代差,我认为至少有三年。
但是如今大家都能看到中国像DeepSeek, Qwen等等。包括MiMo在内的开源模型。其实距离世界的顶尖的闭源模型的差距可能这个差距只有数月了。
我们相信开源的价值并不仅仅是说我们分享了模型,分享了代码。
而我,开源的价值本质上是一种分布式的技术的加速的主义。我认为开源是实现AGI的普惠化是确保所有人类的智慧共同进化的唯一路径。
从数据的极致压缩到算法的范式创新,再到与物理空间的深度链接,小米与全球AI共同定义未来。谢谢大家。

以上となります。
日本語訳全文は、当社noteをご覧ください。
また、「CN.科技发布会」チャンネルから、プレゼンの様子を動画で見ることもできますので、ご興味を持った方は、検索されてみていはいかがでしょうか?

コメント